
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 동시성 제어
- 스프링오류
- Jenkins
- Mysql이미지
- 대규모 트래픽
- 분산시스템
- 스프링기초
- 자바
- 스프링Entity
- 토스책
- JavaScript
- OS
- nestjs 예외
- 스프링jpa
- docker
- 3WayHandshake
- 유난한 도전
- 트러블슈팅
- 예외 커스텀
- nodejs
- 스프링
- connection reset by peer
- nginx
- nestjs
- 토스팀
- 동시성 문제
- 스프링 이미지
- 동시성문제
- 예외필터
- 예외 핸들링
- Today
- Total
삽질블로그
치킨 디도스 프로젝트(1) 본문
Algorithm Review 프로젝트를 끝내고 AWS에서 이것저것 테스트를 진행해볼까 하다가
로컬에서 우선 이것저것 해보고 싶은 마음에 새로운 프로젝트를 진행하게 되었다.
내가 가장 경험해보고 싶은 것은
1. 동시성 문제 해결
2. 분산 시스템 구축
다음과 같은 경험을 하고 싶었다.
크게 read와 write로 나눴고 어떤 프로젝트를 하는게 좋을까 하다가
쿠폰에 환장하는 나같은 사람들은 선착순 치킨 쿠폰 이벤트가 열리면 서버에 엄청난 트래픽을 주기 때문에
그 트래픽이 마치 디도스 같아 프로젝트명을 치킨 디도스로 정했다ㅋ.ㅋ
그럼 차근차근 단계를 밟아보자.
프로젝트의 요구사항은 다음과 같다.
사용자는 다음 임의의 쿠폰 중 한 개를 선착순으로 발급받을 수 있다.
중복 발급은 불가능하며, 쿠폰 종류는 3개가 존재한다.
쿠폰 A : 할인율 100%, 수량 : 100장, 쿠폰코드 : A001
쿠폰 B: 할인율 50%, 수량 : 500장, 쿠폰코드 : B001
쿠폰 C: 할인율 10%, 수량 : 1000장, 쿠폰코드 : C001
이 프로젝트는 핵심 아이디어만 보여주기 위해 다음과 같은 상황으로 가정한다.
1. MSA 아키텍처라고 가정 -> 사용자의 인증, 인가 등의 검증 기능은 사용하지 않는다.
2. 쿠폰의 정보는 미리 데이터베이스에 저장되어 있다고 가정한다.
다음과 같은 요구사항과 아이디어를 어떻게 구현할지 처음부터 단계를 밟아보도록 하려한다.
먼저 첫 번째 동시성 문제를 고려하지 않고 코드를 작성해보자. 여기서 서버의 부하, 분산 문제는 고려하지 않도록 한다.
기술스택
- Langauge: Javascript
- Framework: Nestjs
- Database: Mysql
- Monitoring : prometheus, grafana, InfluxDB
- Test Tool : K6
데이터베이스 ERD는 다음과 같이 단순하게 구성했다.
1. 쿠폰 정보를 담을 수 있는 쿠폰 테이블
2. 쿠폰을 수집하는 쿠폰지갑 테이블

첫 번째로 가정한 것은 다음과 같다.
1. 데이터베이스에 락 없이 동시 트래픽이 쏠릴 때 데이터베이스의 무결성 위반과 동시성 문제가 언제부터 발생하는가?

다음과 같이 Coupon테이블을 초기화 시켜준 후에 테스트를 시작해보았다.
10초 동안 3명의 사용자가 각각 3번씩 요청을 날리면 결과가 어떻게 될지 확인해보자.

다음과 같이 쿠폰지갑에 정상적으로 유저가 들어온 것을 확인할 수 있다.
이 테이블만 보고 이 코드가 정상적으로 동작했다고 생각하면 안된다.
데이터베이스의 일관성을 유지하고, 동시성 문제에서 발생할 수 있는 데이터 무결성 위반이 발생했는지 확인해야 한다.

이 테이블에서 A001의 남은 쿠폰의 개수를 확인해보자.
총 발급된 쿠폰이 3개인데 남은 쿠폰은 98개인 것을 확인할 수 있다.
이는 데이터베이스의 동시성 문제가 발생했기 때문에 데이터가 올바르게 업데이트 되지 않았다고 볼 수 있다.
따라서 데이터베이스의 정확성, 일관성, 유효성을 유지하지 못한 상태이기 때문에 데이터 무결성을 위반했다고 볼 수 있다.
표본이 진짜 작음에도 불구하고 이런 문제가 발생했다.
이러한 문제를 해결하기 위한 방법으로 데이터베이스에 락을 거는 방법이 있다.
1. 비관적 락 : 비관적 락은 Repeatable Read 또는 Serializable 정도의 격리성 수준을 제공
2. 낙관적 락 : 자원에 락을 걸지 않고, 동시성 문제가 발생하면 그때 처리
3. 분산 락 : 여러 서버가 공유 데이터를 제어하기 위한 기술
여기서 분산 락은 논외로 하고 나는 여기서 비관적 락을 선택하기로 결정했다.
이유는 각 락의 특성을 살펴보면 알 수 있다.
비관적 락
- 주로 데이터 충돌이 자주 발생할 것으로 예상되는 환경에서 사용
낙관적 락
- 데이터 충돌이 드물다고 가정하고, 충돌이 발생했을 경우에만 롤백하거나 재시도하는 방식
쿠폰 이벤트 같은 경우 데이터 한 순간에 트래픽이 몰리기 때문에 데이터 충돌이 자주 발생한다고 가정했기 때문에
비관적 락을 선택했다.
그럼 기존의 코드를 비관적 락을 사용한 코드로 수정 후 테스트를 다시하면 어떻게 될까


다음과 같이 A001을 선착순 쿠폰이 3명의 사람에게 정상적으로 발급된 것을 확인할 수 있다.
이제 데이터베이스의 자체 락을 통해 동시성 문제를 해결했는데 이 서버가 어느 정도의 트래픽을 받을 수 있나 확인해보고자 한다.
첫 번째 Stress test로 1000명의 유저가 60초 동안 트래픽을 줬을 때의 결과이다.

이를 그라파나랑 연동해서 보면 다음과 같다.

유저 1000명으로 60초간 트래픽을 줬을 때
http_req_duration 즉, 요청을 완료하는데 걸린 총 시간이
평균 1.88s, 최대 2.90s, 최소 0.04ms, 90퍼센트 이상 2.23s, 95퍼센트 이상 2.51s 임을 볼 수 있다.

쿠폰도 정상적으로 발급된 것을 볼 수 있다.
하지만 클라이언트에서 너무 많은 트래픽을 쏘다보니 다음과 같은 오류가 계속해서 발생했다.
error="Post \"http://localhost:8000/coupons/issue\": dial tcp 127.0.0.1:8000: connect: connection reset by peer"
이는 서버가 갑자기 연결을 끊었음을 의미하는데, 클라이언트가 서버로부터 데이터를 읽으려 했지만 서버가 연결을 재설정했다는 뜻이다.
일반적으로 서버가 과부하 상태이거나 서버에 에러가 발생해서 클라이언트의 연결을 더 이상 처리할 수 없을 때 발생한다고 한다.
한편으로 첫 번째 가정에서 1000명의 트래픽은
1. 데이터베이스와 서버를 스케일 아웃하지 않음
2. 캐시를 이용한 분산락을 사용하지 않음
이런 상태에서 준수한 응답시간을 받은 것 같았다. -> 클라이언트 측 오류는 수정해야하지만 말이다.
그래서 10000명으로 다시 스트레스 테스트를 진행해보았는데 결과는 다음과 같다.
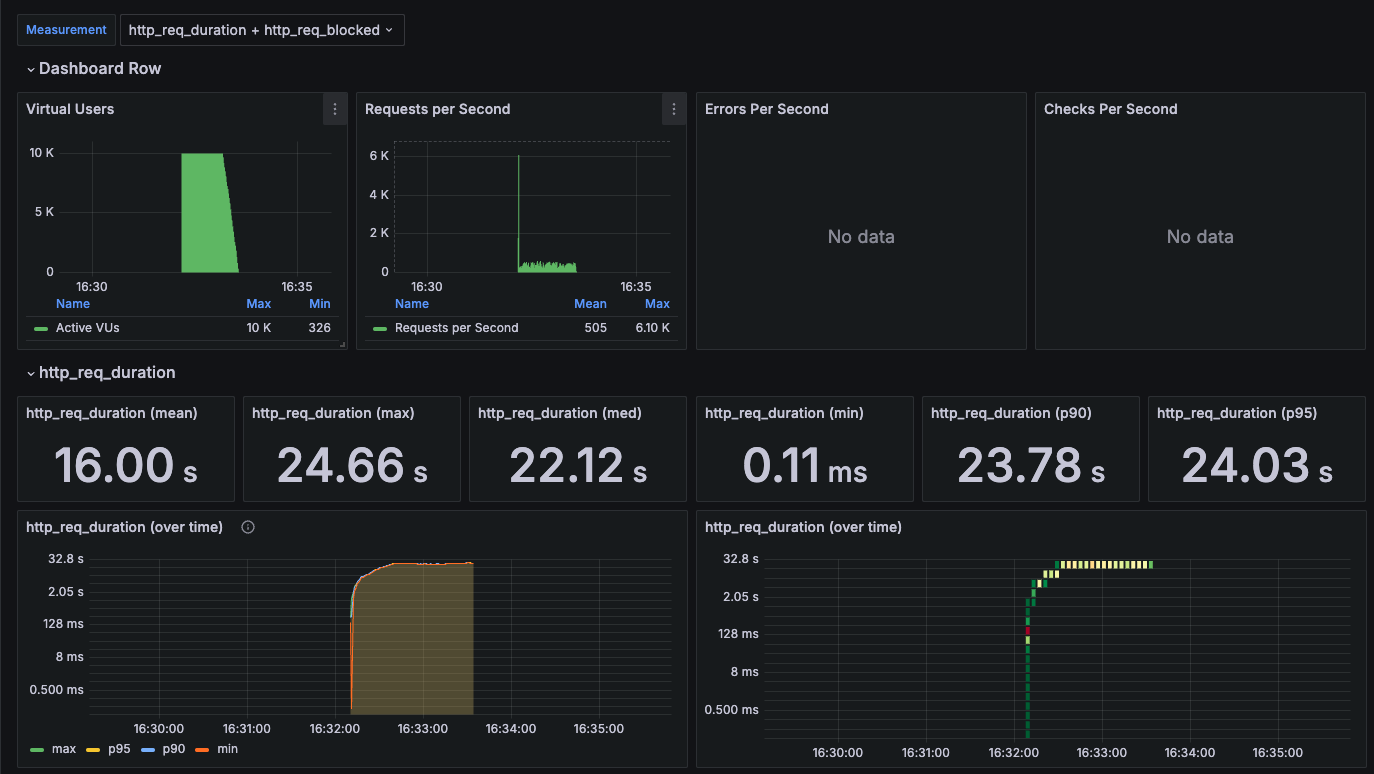
http_req_duration을 보면 16.00s, 24.66s, 22.12s로 매우 늦은 응답시간을 확인할 수 있다.
실제 서비스에서 이런 응답시간을 보여준다면 모든 고객들은 이탈할 것이다......
이제 이 느린 응답시간을 개선하고 나머지 오류들을 해결하는 과정을 가져보자.
'개발' 카테고리의 다른 글
| 치킨 디도스 프로젝트(3) (3) | 2024.09.04 |
|---|---|
| 치킨 디도스 프로젝트(2) (2) | 2024.09.03 |
| NestJS 예외 핸들링 (1) | 2024.07.22 |
| 개인 프로젝트 후기 (3) | 2024.07.19 |
| Docker와 Jenkins를 이용해서 CI/CD를 구축해보자 (1) | 2024.04.16 |



